
Ik heb de boeken op papier gekocht, ik vind dat het dus geen probleem is als ik ze ook digitaal ergens, euh, vind.
En eens ik de boeken digitaal heb, is het natuurlijk gemakkelijk om er dingen mee te doen. Zoals bijvoorbeeld tellen hoeveel keer een woord voorkomt, of het aantal unieke woorden tellen.
Wat een enorm gemak, dat er notebooks in VS Code zitten:
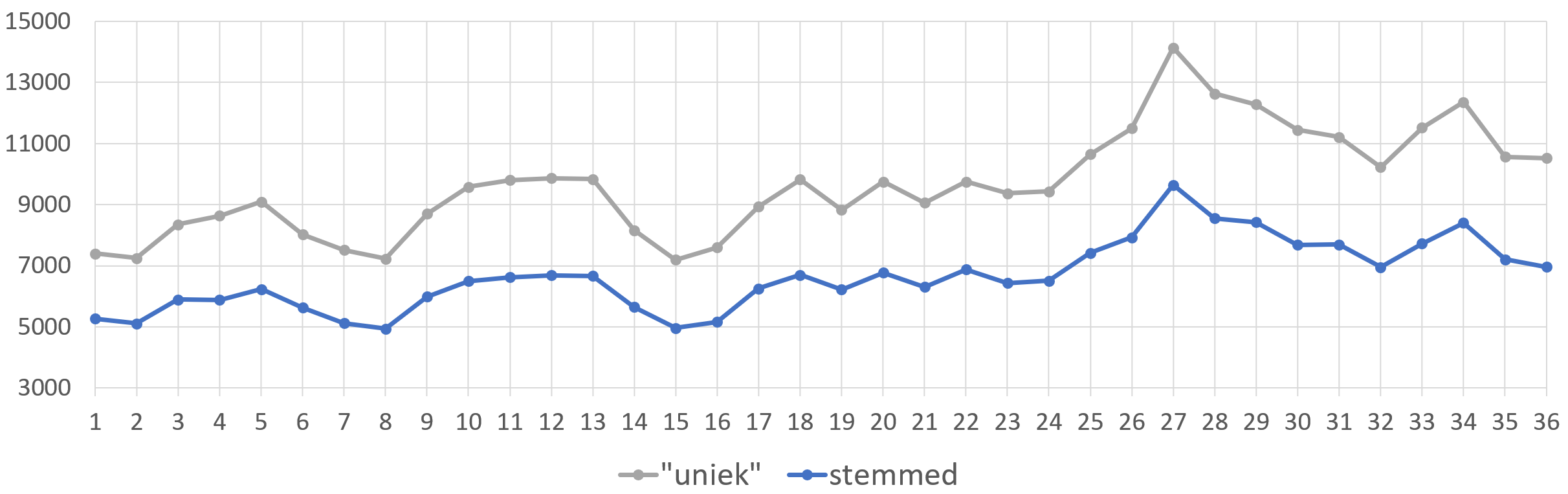
Dat geeft mij het aantal unieke woorden in elk van de 36 Gor-boeken — een totaal van Bijna vierentwintigduizend bladzijden (23.858 om exact te zijn) — op 3.5 seconden. Zot.
Nog meer informatie?
De meest voorkomende woorden zijn (in volgorde) the, I, of, to, and, a, in, she, it, her, not, was, he, you, is, had, that, be, as, on, my, me, with, for, are, slave, at, would, from, his, have, then, they, were, but, or, do, been, asked, master, we, there, this, no, their, by, so, what, might en will.
Allemaal voor de hand liggende woorden — op nummer 26, tussen are en at: slave. En op plaats 40: master. Ja, ’t geeft een beetje een idee waar de auteur van wakker ligt.
…maar dan bedacht ik ineens, bij het bekijken van die meest voorkomende woorden, dat mijn simpel script van hierboven veel té simpel was. Op plaats 39 van alle woorden staat “asked”, dat 21.716 keer voorkomt in de 36 boeken. Maar dat is niet alles: er is ook nog “ask” (plaats 1124), “asking” (3993) en “asks” (9844). Dat geeft de indruk dat er meer woorden zijn dan er eigenlijk gebruikt worden.
Gelukkig is het gemakkelijk om daar een mouw aan te passen: Natural Language Toolkit to the rescue! Ik pak de lijnen in de tekstbestanden, haal er de woorden uit en lemmatiseer ze, ’t is te zeggen, ik haal er het stamwoord uit. Dat maakt van “I am asking you if he was eating” eerst ['I', 'am', 'asking', 'you', 'if', 'he', 'was', 'eating'] en dan ['I', 'be', 'ask', 'you', 'if', 'he', 'be', 'eat'].
Op die manier kom ik op een wat meer correcte inschatting van hoeveel woordenschat in elk boek van de Gor-reeks gebruikt wordt: de blauwe lijn hieronder, as opposed to de grijze lijn die ik daarnet had. Niet dat het uiteindelijk een groot verschil geeft, want de verhoudingen blijven quasi precies gelijk, maar ’t is toch correcter:
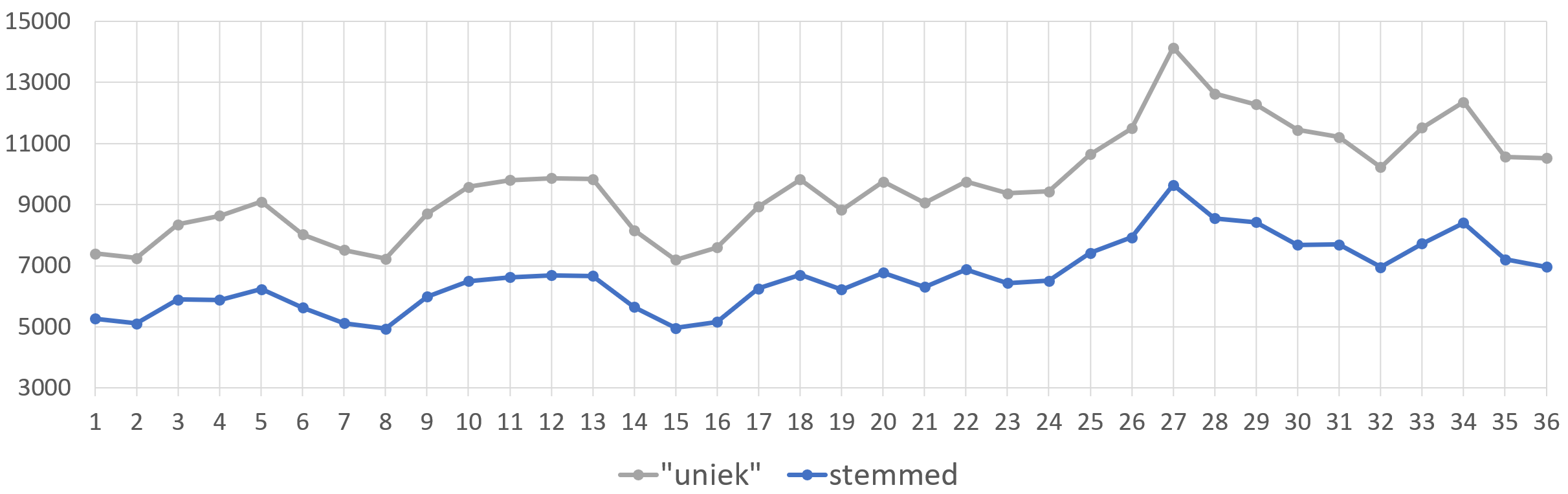
John Norman gebruikt trouwens in totaal 31.878 verschillende woorden in zijn 36 boeken. Dat is iets meer dan Shakespeare — op het internet lees ik dat hij er 31.534 zouden gebruikt hebben in zijn werk, maar als ik precies dezelfde methode op Shakespeare’s verzameld werk loslaat, kom ik zelfs maar op op 26.608 woorden. Het is me d’er eentje, John Norman.
De langste woorden in de Gor-boeken, als ik samengestelde woorden ook meereken, zijn trouwens “at-least-temporarily-inaccessible”, “possibly-looking-for-a-switching” en “hands-behind-the-back-of-the-neck” en “hands-behind-the-back-of-the-head”. Tja.
En er zit ook een propere verdeling in de woorden, qua lengte:
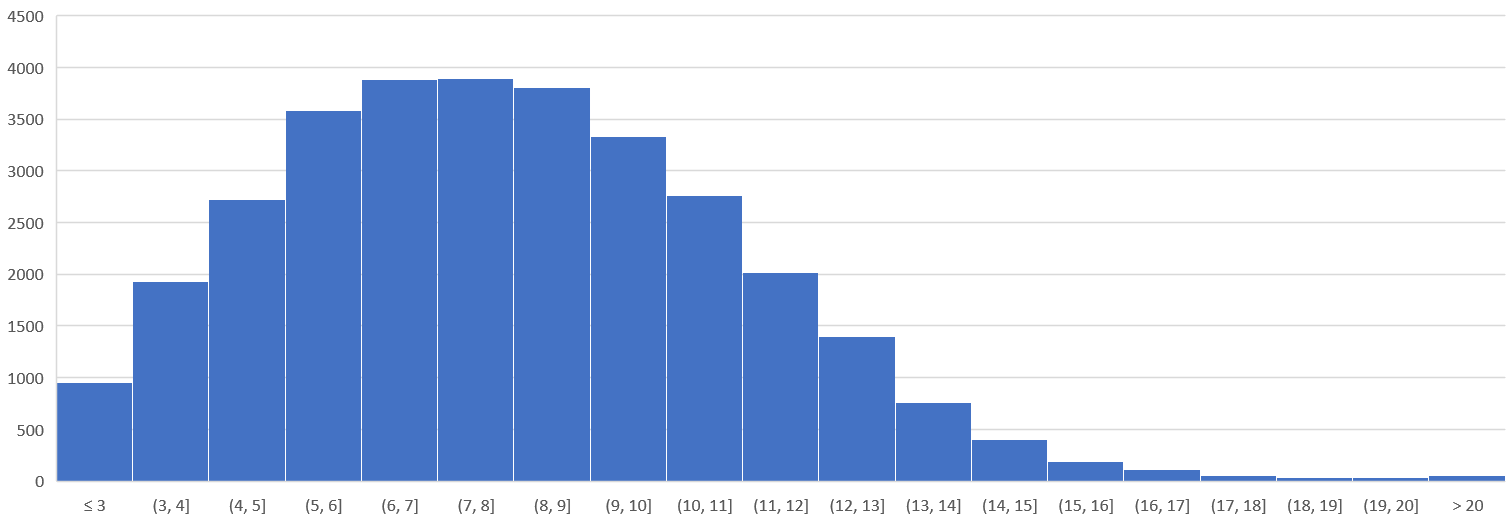
Een mens moet er niet bij stilstaan dat dergelijke dingen vroeger met de hand gedaan werden. Tellen hoeveel woorden er in een boek zijn en zo.
Reacties
2 reacties op “Een gemak”
Je kan ook de TF-IDF per woord berekenen. Dan wordt het nog leutiger. Bijvoorbeeld: https://towardsdatascience.com/text-summarization-using-tf-idf-e64a0644ace3
Ik heb een tijdje geleden al wat geprutst met FT-IDF: https://blog.zog.org/2022/01/zeldzame-woorden.html 🙂
Maar samenvattingen maken ermee lijkt mij ook wel leutig.