
Ik zou het elke dag kunnen zeggen, maar: leve het interwebs! Ik lees een artikel in de New York Times (dat alleen al is fantastisch, dat het praktisch niéts kost om dat elke dag te kunnen lezen, en om te kunnen terugduiken in het hele archief en alles), en via daar kom ik terecht op een artikel dat het heeft over het mogelijk ontcijferen van het schrift van de Indusbeschaving.
Die beschaving heeft het een dikke 2000 jaar uitgehouden, in dezelfde periode als het begin van de beschaving in Mesopotamië en Egypte, maar dan wel over over een veel grotere oppervlakte.
Het is niet zeker welke talen er allemaal gesproken werden (we mogen er van uitgaan dat het er meer dan één was), en het is al helemaal niet geweten hoe het schrift te ontcijferen. Niet alleen is er nergens een steen van Rosetta, maar vooral: er zijn veel inscripties gevonden, maar ze zijn allemaal zeer kort — gemiddeld vijf karakters.
Dus, ik lees dat interessante artikel, dat spreekt over mogelijke toepassingen van AI. Maar hét interessantste van het hele artikel, vond ik, is waar Bahata Ansumali Mukhopadhyay oppert dat het misschien helemaal geen via AI ontcijferbaar ding zou kunnen zijn:
Mukhopadhyay went down one rabbit hole after another. She parsed Mesopotomian, Akkadian, Sumerian, and Old Persian dictionaries. She taught herself how to read Egyptian hieroglyphics. “I realized just how subtle symbolism can be,” she said. “Like the god Horus, his eye was torn into fragments. Each part is imagined as a fraction — and then from there, the ancient Egyptians created their symbols for fractions.”
Even as she helped build software to aid research on the Indus script, her doubts about the approach were building. “See, if the Indus script were an alpha syllabary [a writing system split into units of consonants and vowels, as in Urdu/Hindi], then machine learning and artificial intelligence would have been very suitable,” she explained. But because the inscriptions appear to be pictorial in nature, they posed a greater challenge. “Here you have to understand the historical symbolism used in India. How will artificial intelligence tackle that? How would AI know these symbols represent the fragments of Horus’ eye?”
En natuurlijk, jazeker: het onderzoek van Mukhopadhyay staat ook helemaal online. De paper in Nature is lang maar bijzonder boeiend. (En voor één keer is hij gewoon rechtstreeks leesbaar en moet ik niet via scihub gaan om het paralegaal te bekijken.)
Het komt er in het heel snel op neer dat ze er in slaagt om een reeks patronen te identificeren die altijd voorkomen, en ook de combinaties van dingen, en dat ze daar dan dan (na veel vijven en zessen en uitleg en verantwoording) een voorstel mee formuleer om de inscripties op te delen in betekenisvolle groepen, bijvoorbeeld zo:
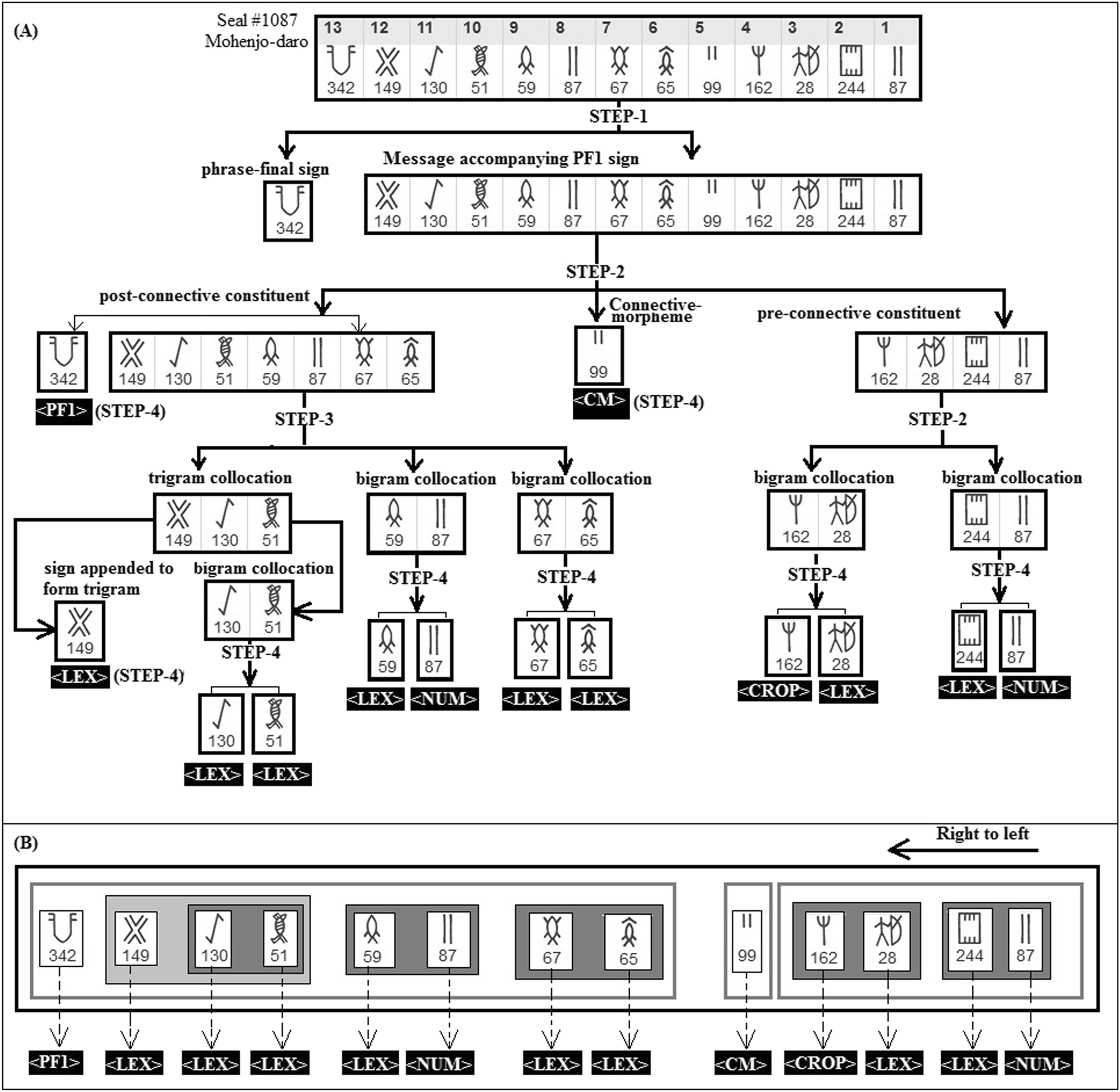
Ze vertrekt van een groep van dertien tekens, die bestaan uit eerst twee groepen van telkens twee tekens, en dan een verbindingsmorfeem, gevolgd door drie groepen van twee (waarvan de laatste een extra teken krijgt om aan te duiden dat hij het derde deel van een groepering is), en dan een afsluitend teken.
Voor de rest verbindt ze geen taal of betekenis aan de tekens, maar geeft ze wel interessante vergelijkingen met muntstukken en postzegels en papiergeld, waar ook telkens formulaïsche combinaties van tekens op staan die nooit via gewone taalanalyse zouden kunnen begrepen worden.
Maar nee serieus: zo boeiend.