
Ik dacht, wij gebruiken op het werk Grafana en dat is eigenlijk wel wijs om data in tijdsreeksen te tonen, en het is al lang geleden dat ik nog eens iets gedaan heb dat ik nog nooit gedaan heb, en waarom dus ook niet?
Zodus. De bedoeling: ik wil een grafiekje zien van zaken die veranderen met de tijd. Te voor de hand liggend: temperatuurgegevens, websitebezoeken, geheugengebruik, dat soort dingen.
Dus op zoek gegaan in de Open Data van de Stad Gent, en een fijne kandidaat gevonden: real-time gegevens over de bezetting van parkings in Gent.
Omdat ik te leeg ben om veel nieuwe dingen te leren, pleeg ik in de rapte iets in python:
import urllib.request, json
url = 'https://datatank.stad.gent/4/mobiliteit/bezettingparkingsrealtime.json'
data = urllib.request.urlopen(url).read().decode('utf8')
parkings = json.loads(data)
for parking in parkings:
plaats = parking['address'].splitlines()[0]
totaal = parking['parkingStatus']['totalCapacity']
over = parking['parkingStatus']['availableCapacity']
ts = parking['parkingStatus']['lastModifiedDate']
with open('parkings.csv', 'a') as plog:
plog.write(ts + ';' + plaats + ';' + str(over) + ';' + str(totaal) + '\n')
plog.closed
Dat leest de json van de Stad Gent in, en dat schrijft lijnen zoals dit naar een bestand:
09/12/2016 20:59:00;Sint-Michielsplein 8;-1;450 09/12/2016 20:58:00;Sint-Pietersplein 65;318;708 09/12/2016 20:59:00;Vrijdagmarkt 1;24;647 09/12/2016 20:59:00;Savaanstraat 13;254;540 09/12/2016 20:59:00;Ramen 23;-3;266 09/12/2016 20:58:00;Seminariestraat 9;9;470
Omdat ik te leeg ben om het echt proper te doen, stamp ik dat in een cron-job die elke minuut loopt.
Zo ver was ik dus deze namiddag toen ik er op gekomen was dat ik dit wou doen. All of een kwartier werk, waarvan het grootste stuk nog was mij afvragen op welke server ik dit zou zetten. 🙂
De data van de afgelopen paar uur eens rap in Excel gesmeten, geeft dat dit:
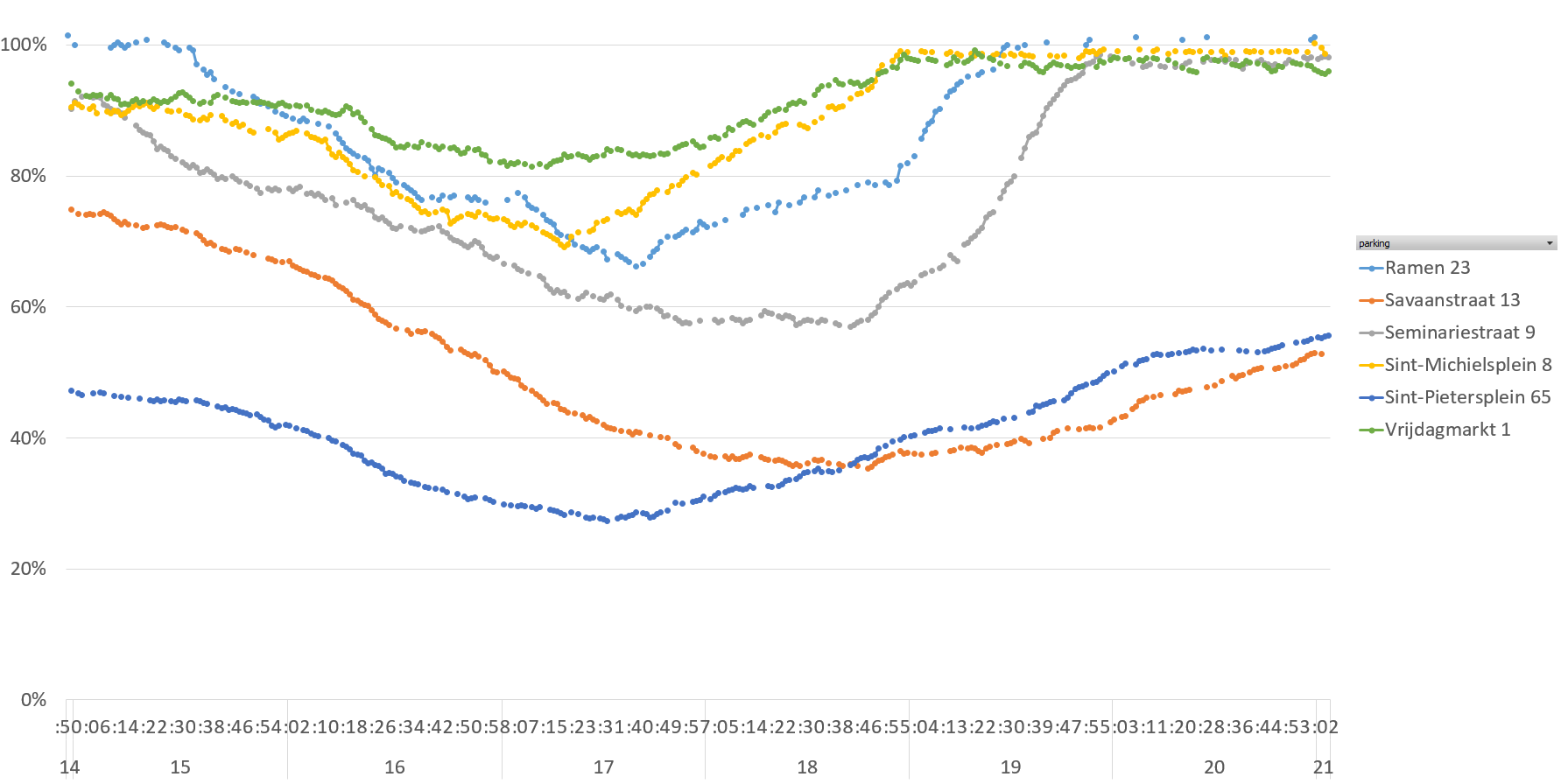
Yep yup, data die er als echte data uitziet. Met het einde van de werkdag lopen de parkings een beetje leeg, en met het begin van de avond lopen ze weer vol. Sint-Michielsplein en Vrijdagmarkt staan tegen 19u al vol, Ramen om 19u30, Vrijdagmarkt om 20u.
De volgende stap is wellicht dat ik de data in graphite zou moeten kunnen gestampt krijgen, maar misschien dat ik eerst eens kijk of ik Grafana op mijn computer krijg…
Yay!
(En ja, ik weet dat dat allemaal zo speciaal niet is. Maar ik blijf het magisch vinden als het werkt. Sue me.)
Bon, zodus. Graphite is iets waar data naartoe gestuurd kan worden. Zo ver zijn we. Dat blijkt een samenraapsel te zijn van graphite-web, carbon, whisper en ceres.
Euh ja. Ik ga gewoon de handleiding afgaan en zien waar ik uitkom.
Downloaden en installeren, geen probleem. Configuring Carbon: geen idee wat ik aan het doen ben, ik laat alles op defaultwaarden staan en ik zie waar ik uitkom. 🙂
Op naar Feeding Carbon. Plaintext zal wel genoeg zijn, zeker? Eerste test, gewoon doen wat de handleiding zegt:
$ PORT=2003
$ SERVER=localhost
$ echo "local.random.diceroll 4 `date +%s`" | nc -q0 ${SERVER} ${PORT}
Geen foutboodschappen, ’t is altijd dat. Maar heeft dat nu ergens iets ingestoken? Geen idee. Verder doen, dan maar. Ik zou het liefst gewoon al wat echte data erin proberen smijten. Eens kijken of er niets is dat logfiles naar graphite smijt?
Ha, jawel. Etsy’s logster. Download, install, kijken wat dat doet. Het klaagt niet. Ik ga ervan uit dat het iets gedaan heeft.
Terug naar graphite. Administering Carbon. Ha, leutig, dependencies. Hij heeft nog twisted nodig, en daemonize.
Oh, check it out, “ImportError: cannot import name daemonize”. Blijkbaar moet ik een oudere versie van twisted installeren. Een welgemikte pip install 'Twisted<12.0' en kijk nu: starting carbon-cache (instance a).
“Now is a good time to check the logs, located in /opt/graphite/storage/log/carbon-cache/ for any errors.” Okay, ik zie geen fouten staan. So far so good.
En dan klik ik op de volgende pagina, en oh never mind. De pagina daarna? Oh never mind.
Bon.
Dit is mij echt veel te veel soep. Alle begrip dat het fantastisch is als het is gelijk bij ons op het werk met miljarden datapunten per dag en alles, maar ik denk dat het een beetje overkill is voor een bestandje dat och here maximaal 8640 lijnen per dag zal bevatten.
Eens kijken naar de volgende optie op de lijst “input voor Grafana”: InfluxDB.
Installeren geen probleem, aan de praat krijgen ook geen probleem. Ik zie een python-client om er data in te smijten, en dat geraakt ook zonder problemen draaiend:
Veelbelovend.
Krijg ik dat nu in Grafana? Euh ja, blijkbaar dus wel. “Data source is working” is een fijne boodschap.
Dan gaan we dus maar wat open data inlezen en naar een andere jsonformaat omzetten zeker? Ik heb iets nodig in deze zin:
{
"measurement": "bezetting",
"tags": {
"parking": "naam van de parking"
},
"time": "2016-12-10T23:00:00Z",
"fields": {
"beschikbaar": 200,
"totaal": 350
}
}
…en jawel, dat lukt proper. ’t Is te zeggen: het geraakt in influx, ik krijg er proper uit, maar ik krijg het niet te zien in Grafana.
Kak.
(Een half uur later: nog altijd kak. Ik heb alles gebrobeerd en ik vind het niet. Ik ben het beu. Ik ga iets anders doen.)
(Anderhalf uur ‘iets anders doen’ later: MILJAARDEDJU het is een yyyy/mm/dd versus yyyy/dd/mm-verwarring.
Hopla, data in de database en op Grafana.
Voor de leutigheid een import doen van de csv die aan het collecteren was sinds deze middag, en het kan niet gemakkelijke zijn met Influx: eerst een database aanmaken in influx, pakweg “parkingen”, en dan een file als deze maken:
# DML
# CONTEXT-DATABASE: parkingenbezetting,parking=Sint-Pietersplein beschikbaar=376,totaal=708,procent=0.468926553672316 1481296020
bezetting,parking=Vrijdagmarkt beschikbaar=49,totaal=647,procent=0.924265842349304 1481296020
bezetting,parking=Savaanstraat beschikbaar=139,totaal=540,procent=0.742592592592593 1481296020
bezetting,parking=Seminariestraat beschikbaar=38,totaal=470,procent=0.919148936170213 1481296020
Op elke lijn drie items, gescheiden met een spatie:
- de measurement en eventueel één of meer tags — in mijn geval bezetting en parking
- één of meer fields — in mijn geval beschikbaar, totaal en procent (omdat ik geen zin had om het te berekenen in Grafana)
- een timestamp (helaas ondersteunt Influx blijkbaar alleen UTC, awoert)
Dat wordt in Influx gesmeierd met
$ influx -import -path=data.txt -precision=s
en hopla, 2275 inserts, en stof om een eerste dashboard te maken.
Een grafiekje van de procenten bezetting van elk van de parkings is iets als dit:
SELECT mean("procent") FROM "bezetting" WHERE $timeFilter
GROUP BY time($interval), "parking" fill(null)
terwijl het aantal vrije plaatsen in één parking iets als dit is:
SELECT mean("beschikbaar") FROM "bezetting" WHERE "parking" = 'Savaanstraat' AND $timeFilter GROUP BY time($interval) fill(null)
En meer moet dat niet zijn (klik voor detail):
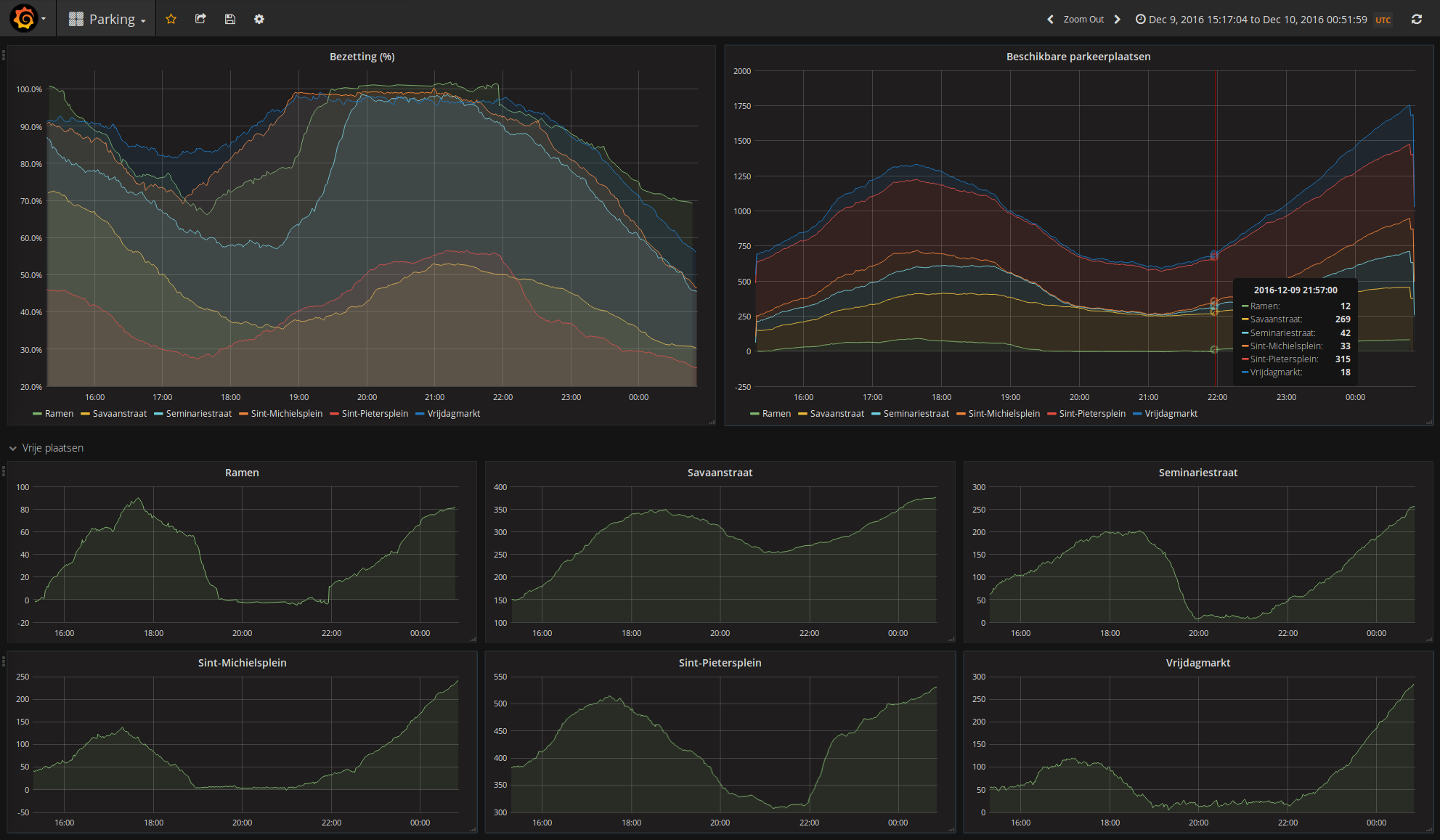
Dat was wijs.
Nu alleen nog dat Pythonscriptje aanpassen om de data rechtstreeks in Influx te smijten en het doet al wat het zou moeten doen.
En dan zou ik eigenlijk allerlei andere opendata-dingen kunnen toevoegen ook, en Gent op de voet volgen MWAHAHAHA.
update en hopla, dit is automatisch en alles:

Reacties
3 reacties op “Prutsen met data”
zalig, en waar kunnen we dat nu live volgen? want dat interesseert me wel 😀
Oei, live. Ik heb een snapshot op https://snapshot.raintank.io/dashboard/snapshot/pbvuK7HBlP34NigvWi0ayOJrnctJ2cmA gezet, maar ik zou eens moeten kijken waar ik nog een publieke server staan heb die dat zou kunnen doen. 🙂
wij volgen u ook. MWOOEHAAHAHAAAH. 🙂